
很多時候我們網站中的一些頁面不想被搜索引擎收錄,哪些頁面呢?比如自己網站中內部網站,僅供內容員工使用的網站功能模塊,這些模塊是我們在網站建設的時候就要做好規劃的,這部分我們可以使用ROBOTS的方式讓搜索引擎不收錄。
robots.txt正確寫法
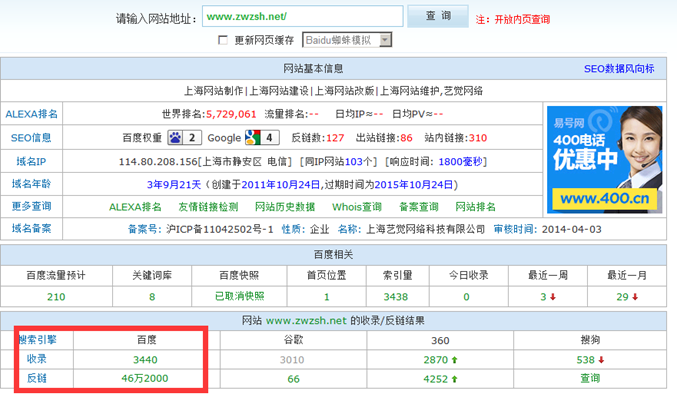
正如前面提到的,一些頁面我們不想讓百度和google收錄,那怎么辦?我們可以告訴搜索引擎,和搜索引擎達成一個約定,如果我們按約定那樣做了,它們就不要收錄,寫一個robots.txt文件。
這個寫約定的的文件命名為:robots.txt。robots.txt是一個最簡單的.txt文件,用以告訴搜索引擎哪些網頁可以收錄,哪些不允許收錄。
網站建設時robots.txt需要注意以下幾點:
如果你的站點對所有搜索引擎公開,則不用做這個文件或者robots.txt為空就行。文件名字必須命名為:robots.txt,都是小寫,并且要注意拼寫的正確性,robot后面加"s"。很多網站制作的朋友比較大意,拼寫錯誤讓工作白做了。
再就是robots.txt必須放置在一個站點的根目錄下。如:通過http://www.....cn/robots.txt 可以成功訪問到,這就說明我們的文件的位置放置正確。一般情況下,robots.txt里只寫著兩個函數:User-agent和 Disallow。有幾個需要禁止,就得有幾個Disallow函數,并分行描述。至少要有一個Disallow函數,如果都允許收錄,則寫: Disallow: ,如果都不允許收錄,則寫:Disallow: / (注:只是差一個斜桿)。
以上是上海網站制作公司總結出來的幾個要點,針對不允許搜索引擎收錄的處理方式,供大家參考。
本文由上海藝覺網絡科技有限公司(http://m.gxxmybkw.com)原創編輯轉載請注明。



